AI한테 문서 던져주고 '해줘'만 하면 절대 안 되는 이유
같은 AI인데 왜 나는 되고 너는 안 될까? 팀원의 반나절 삽질을 30초로 줄인 한 가지 차이.

들어가며
최근 팀에 AI 코딩 도구를 도입하면서 재미있는 걸 발견했다. 같은 AI를 쓰는데 사람마다 결과가 완전히 다르다.
우리 팀원 중 한 명이 사내 스토리지 API를 연동하는 작업을 맡았다. 이 API가 좀 까다로웠다. 인증 방식이 독특하고, 멀티파트 업로드에 서명 과정이 복잡하고, 에러 응답 형식도 일반적이지 않았다. 공식 문서를 다 줘도 한 번에 되는 류의 작업이 아니었다.
팀원은 AI에게 문서를 전부 넘기고 구현을 시켰다. 코드가 나왔다. 당연히 한 번에 되진 않았다. 그리고 여기서부터 문제가 시작됐다.
 image-2026-02-17-175313
image-2026-02-17-175313
사람이 루프에 끼는 방식
팀원의 작업 방식은 이랬다.
1. AI에게 구현 요청
2. AI가 코드 작성
3. 사람이 직접 앱을 실행해서 테스트
4. 실패 → 에러 로그를 복사
5. AI에게 에러 로그 전달하며 수정 요청
6. AI가 수정
7. 다시 3번으로...
얼핏 보면 합리적이다. AI가 코드를 짜고, 사람이 검증하고, 문제가 있으면 다시 고치는 루프. 하지만 이 방식에는 치명적인 병목이 있다. 사람이 루프 안에 들어가 있다.
AI가 코드를 수정할 때마다 사람이 직접 앱을 빌드하고, 실행하고, API를 호출하고, 응답을 확인하고, 에러 로그를 찾아서 복사하고, 다시 AI에게 전달해야 한다. 수정 한 번에 5~10분. 이걸 열 번 반복하면 반나절이 간다.
더 큰 문제는 따로 있다. 사람이 로그를 잘못 읽거나, 관련 없는 로그를 전달하거나, 핵심 에러 메시지를 빠뜨리는 순간 AI는 엉뚱한 방향으로 수정을 시작한다. 사람이 디버깅 정보를 정확히 전달하는 것 자체가 또 하나의 기술인데, AI 개발에 아직 익숙하지 않은 팀원에게는 그게 쉽지 않았다.
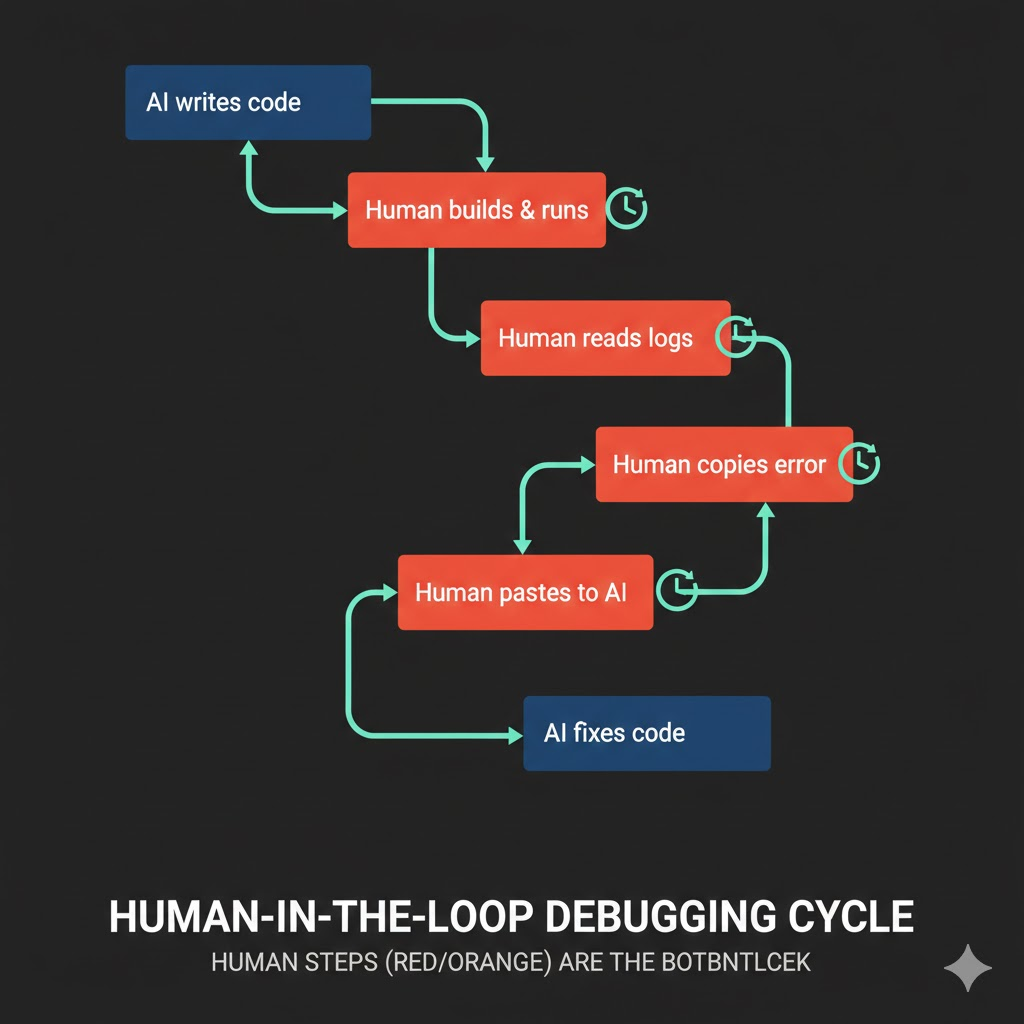 image-2026-02-17-175305
image-2026-02-17-175305
AI가 루프를 돌게 하는 방식
옆에서 보다가 팀원에게 다른 방식을 제안했다.
1. AI에게 구현 요청 + 테스트 코드 작성 지시
2. AI가 코드 작성
3. AI가 직접 JUnit 테스트 실행
4. 실패 → AI가 직접 에러 로그 확인
5. AI가 스스로 수정
6. 다시 3번으로... (테스트 통과할 때까지)
차이가 보이는가? 사람이 루프에서 빠졌다.
AI에게 "스토리지 API에 파일을 업로드하는 코드를 짜줘"가 아니라, **"스토리지 API에 파일을 업로드하는 코드를 짜고, JUnit 테스트를 만들어서 실제로 업로드가 되는지 검증해줘. 테스트가 통과할 때까지 반복해줘"**라고 말하는 거다.
이렇게 하면 AI는 스스로 코드를 고치고, 테스트를 돌리고, 실패하면 로그를 읽고, 다시 고치고, 다시 테스트를 돌린다. 한 사이클에 30초도 안 걸린다. 사람이 하면 5~10분 걸리던 루프가 AI 혼자 돌리면 몇십 초 만에 끝난다.
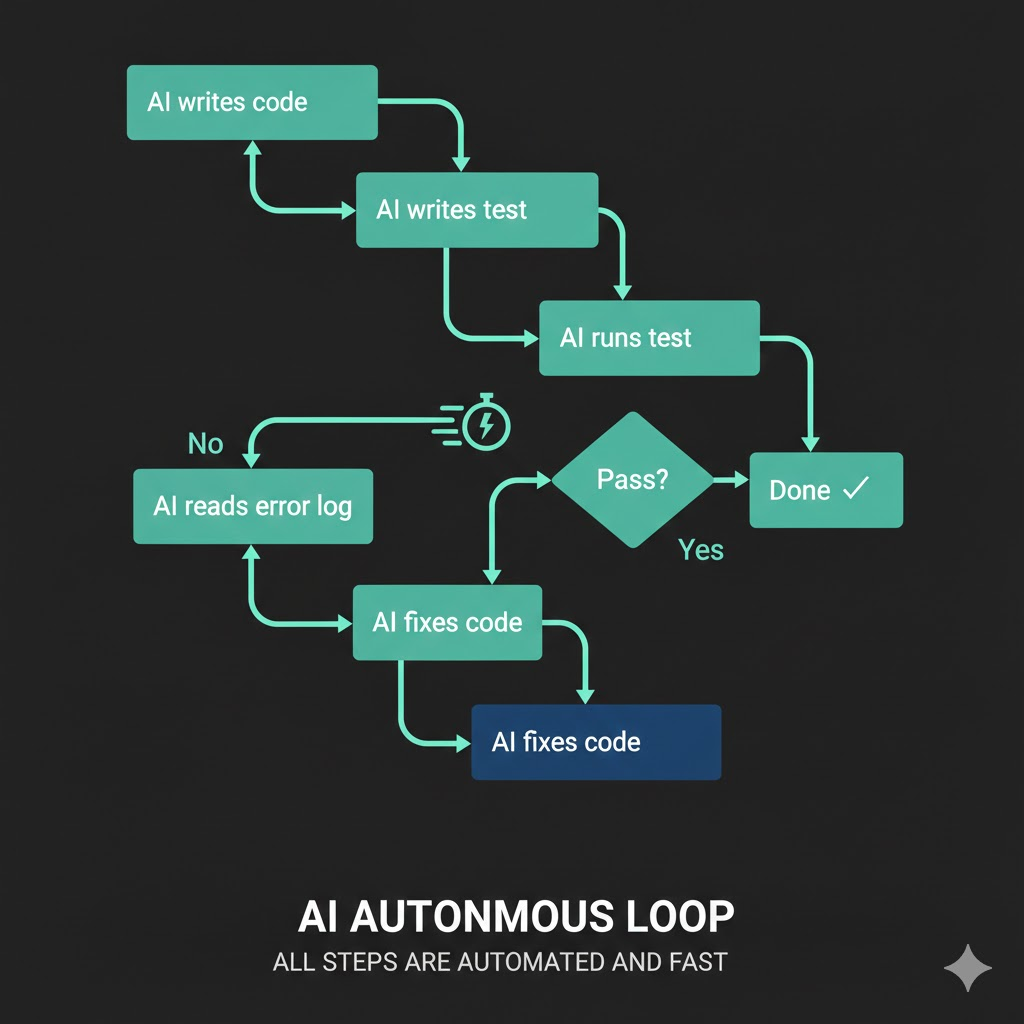 image-2026-02-17-175345
image-2026-02-17-175345
핵심은 '검증 가능한 목표'
여기서 하고 싶은 이야기의 핵심이 나온다.
AI에게 일을 시킬 때 가장 중요한 건, AI가 스스로 "됐다" 혹은 "안 됐다"를 판단할 수 있는 명확한 목표를 주는 것이다.
"스토리지 API 연동해줘"는 목표가 아니다. AI 입장에서는 코드를 작성한 순간 "했다"고 판단한다. 컴파일이 되든 안 되든, API 호출이 성공하든 실패하든, AI는 자기가 만든 코드가 동작하는지 알 방법이 없다. 그래서 사람에게 결과를 넘기고 끝난다.
반면 "스토리지 API에 파일을 업로드하고 JUnit 테스트가 통과하게 해줘"는 검증 가능한 목표다. AI는 테스트를 실행해서 초록불이 뜨는지 빨간불이 뜨는지 스스로 확인할 수 있다. 빨간불이면 아직 안 된 거고, 초록불이면 된 거다.
| 모호한 지시 | 명확한 목표 | |
|---|---|---|
| 지시 | "스토리지 API 연동해줘" | "스토리지 API 업로드 구현하고 테스트 통과시켜" |
| AI의 판단 기준 | 없음 (코드 작성 = 완료) | 테스트 통과 여부 |
| 실패 시 | 사람이 개입해야 함 | AI가 스스로 재시도 |
| 루프 속도 | 5~10분/회 (사람 포함) | 30초/회 (AI 단독) |
 image-2026-02-17-175421
image-2026-02-17-175421
이 개념, 업계에서는 "Ralph Loop"라고 부른다
사실 이 접근법은 이미 업계에서 하나의 패러다임으로 자리 잡고 있다. Ralph Loop라고 불린다.
심슨 가족의 랄프 위검(Ralph Wiggum)에서 이름을 따왔다. 계속 실패해도 끈질기게 반복하는 캐릭터. AI 에이전트도 그렇게 만들자는 거다.
핵심 구조는 놀랍도록 단순하다.
while :; do
cat PROMPT.md | claude-code --continue
doneAI가 작업을 끝냈다고 멈추면, 외부 스크립트가 다시 프롬프트를 주입한다. AI는 파일 시스템과 Git 히스토리를 보고 이전 작업을 이어간다. 객관적인 완료 기준을 만족할 때까지 무한 반복.
기존의 ReAct(Reasoning + Acting) 패턴과의 결정적인 차이는 여기에 있다.
| ReAct | Ralph Loop | |
|---|---|---|
| 종료 판단 | AI가 "충분하다"고 스스로 판단 | 테스트 통과 등 객관적 기준 충족 |
| 문제점 | AI가 조기 종료할 수 있음 | 기준 미달이면 강제 반복 |
| 피드백 | 단일 세션 내 맥락 | 파일·Git 기반 외부 상태 |
앞에서 팀원에게 제안한 방식이 바로 이 Ralph Loop의 축소판이었던 셈이다. "JUnit 테스트가 통과할 때까지 반복해"는 곧 "객관적 기준을 만족할 때까지 루프를 돌려"와 같은 말이다.
 image-2026-02-17-175448
image-2026-02-17-175448
이건 단순히 '테스트 짜라'는 이야기가 아니다
오해하면 안 된다. 이건 "테스트 코드를 짜라"는 이야기가 아니다. AI가 스스로 완료 여부를 판단할 수 있는 피드백 루프를 만들어줘라는 이야기다.
테스트 코드는 그 수단 중 하나일 뿐이다. 상황에 따라 다른 형태가 될 수 있다.
- API 연동: JUnit 테스트로 실제 API 호출 결과 검증
- UI 작업: "브라우저에서 http://localhost:3000을 확인하고 스크린샷을 찍어서 레이아웃이 맞는지 확인해"
- 데이터 파이프라인: "쿼리 결과가 기대값과 일치하는지 assert"
- 인프라 설정: "curl로 헬스체크 엔드포인트를 호출해서 200이 오는지 확인해"
공통점은 하나다. AI가 직접 실행해서 성공/실패를 판단할 수 있는 구체적인 검증 수단이 있다는 것.
실전 프롬프트 비교
이론은 됐고, 실제로 어떻게 지시하면 되는지 비교해보자.
Before: 모호한 지시
사내 스토리지 API 문서야. 이걸 보고 파일 업로드 기능을 구현해줘.
[API 문서 첨부]
AI는 문서를 읽고 코드를 작성한다. 끝. 동작하는지는 모른다.
After: 검증 가능한 목표
사내 스토리지 API 문서야. 파일 업로드 기능을 구현해줘.
[API 문서 첨부]
구현 후 반드시 다음을 수행해:
1. JUnit 테스트를 작성해서 실제 API로 파일 업로드를 테스트해
2. 테스트에서 업로드 후 파일 목록 조회로 실제 업로드 됐는지 검증해
3. 테스트가 통과할 때까지 코드를 수정하고 반복해
4. 최종적으로 모든 테스트가 초록불일 때 완료로 판단해
같은 AI, 같은 문서, 같은 작업. 지시 방식만 바꿨을 뿐인데 결과가 완전히 달라진다.
이건 AI만의 이야기가 아니다
사실 이건 사람에게 일을 시킬 때도 마찬가지다.
주니어 개발자에게 "스토리지 API 연동해줘"라고 하면, 코드를 짜고 "했습니다"라고 보고할 것이다. 그런데 "스토리지 API 연동하고, 테스트 통과시키고, 스테이징에서 실제 업로드 되는 거 확인한 다음에 보고해줘"라고 하면, 본인이 알아서 디버깅하고 검증까지 끝낸 뒤에 보고한다.
명확한 완료 조건이 자율적인 문제 해결을 이끌어낸다. AI든 사람이든.
다만 AI에게는 이게 더 극적으로 작동한다. 사람은 "해봤는데 안 됩니다"라고 말할 수 있지만, AI는 검증 루프가 없으면 안 되는 줄도 모르고 "했습니다"라고 답하기 때문이다.
더 나아가면: 에이전트 팀
이 루프 개념을 더 확장하면, 최근 주목받는 에이전트 팀(Agent Teams) 패턴이 된다. Claude Code의 경우 여러 에이전트 인스턴스가 팀을 이뤄서, 한 에이전트는 기능을 구현하고 다른 에이전트는 테스트를 작성하고 또 다른 에이전트는 코드 리뷰를 하는 식이다.
Anthropic이 실제로 16개의 에이전트 팀으로 Rust 기반 C 컴파일러를 만들어 Linux 커널을 컴파일하는 데 성공한 사례도 있다. 2,000번의 세션, 10만 줄의 코드. 이것도 결국 핵심은 같다. 각 에이전트에게 **"Linux 커널이 빌드되어야 한다"**는 검증 가능한 목표가 있었기에 가능했다.
하지만 에이전트 팀은 다음 단계 이야기다. 지금 당장 중요한 건 단일 AI와의 대화에서도 검증 루프를 심어주는 것이다.
마무리
정리하면 간단하다.
- AI에게 '해줘'가 아니라 '되게 해줘'라고 말하라
- '됐다'를 AI가 스스로 판단할 수 있는 검증 수단을 함께 줘라
- 사람이 루프에 끼지 마라. AI가 루프를 돌게 하라
업계에서는 이걸 Ralph Loop라 부르고, 더 크게 확장하면 에이전트 팀이 된다. 하지만 거창한 이름이 중요한 게 아니다. AI 도구의 성능은 계속 좋아지고 있지만, 아무리 좋은 도구도 목표 없이 쓰면 시간만 낭비된다. 명확한 목표를 심어주는 것. 그게 같은 AI를 써도 결과가 달라지는 이유다.